 当前位置:
当前位置:服务热线
0755-83647532

发表日期:2017-01-19 文章编辑:管理员 阅读次数:
2017年伊始,基于人工智能(AI)的棋手Master在网络快棋比赛中连续击败围棋界的所有顶尖高手,豪取60连胜,人类棋手在人工智能面前毫无还手之力。微信君预测,人工智能依然会在2017年科技热词中占据一席之地。近年来,包括深度学习(Deep Learning)、机器学习(Machine Learning)在内的技术以一种前所未有的力量改变着我们的科技和生活,创造着一个又一个新的记录。
基于多层神经网络的海量数据深度学习
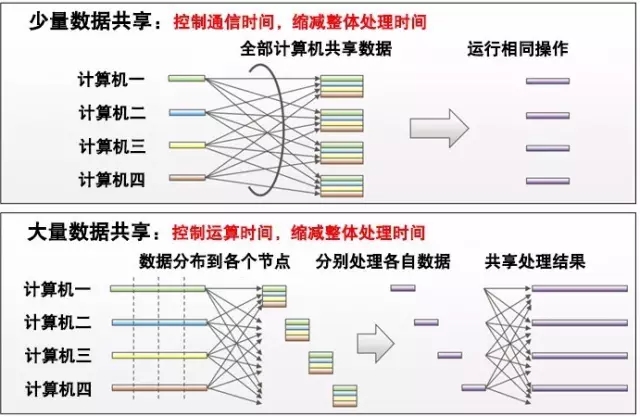
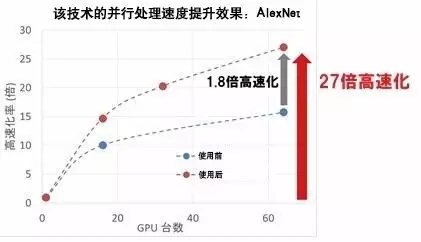
人工神经网络(注1)利用海量数据进行反复多次的学习,并通过这一方法来提高识别与分类的精度。近年来,人工神经网络的研究得到长足发展,特别是在图像识别、文字识别以及声音识别方面,人工智能的精确度已经超越了人类。 深度学习通过处理海量数据来提升精度,因此,在处理速度上比传统CPU更具优势的GPU(注2)得到了广泛的应用。特别是近年来,神经网络多层化的趋势得到了大规模发展,海量数据学习需要耗费大量时间,利用多个GPU并行处理,实现高速化的技术受到了越来越多的关注。 一台计算机搭载的GPU数量有限,因此可以利用高速网络实现多个计算机的GPU互连,在进行数据共享的同时推进机器学习处理。然而,由于数据共享的复杂性以及计算机互连需要额外的通信时间,并行处理的运算速度会受到影响。此外,GPU上搭载的内存量通常较小。这些都成为限制神经网络实现高速学习的课题。 (注1)它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。 (注2)图形处理器(英语:Graphics Processing Unit,缩写:GPU),是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上进行图像运算工作的微处理器。 推进深度学习的高速化与规模化 为了解决上述课题,富士通研究所开发了两项创新技术: 深度学习高速化处理技术 该技术能够自动控制数据传输的优先顺序,使得下一步学习处理所需要的数据能够事先进行共享。采用富士通开发的数据处理技术,在第二阶段开始之前,就启动第一层的数据共享处理任务,使得开启第二阶段的等待时间得到了大幅缩减。对比如下图: 针对计算机共享的处理结果,当原始数据较小时,每台计算机共享数据然后进行相同的操作,消除了结果传输所需的时间;当原始数据较大时,处理任务会分配到各个节点,处理结果也会在每台计算机间进行共享。通过基于数据量来自动分配最佳的操作方法,该技术能够最大限度地减少总体操作时间,如下图: GPU内存效率化技术 富士通研究所开发的这项技术,能够提升内存使用效率,利用一台GPU的计算能力来扩大神经网络规模,避免了使用并行方法导致的学习速度降低问题。通过内存资源的重复利用,该技术能够降低内存用量。当启动学习时,神经网络中每一层的结构都将进行分析,并相应调整运算顺序,以便分配内存空间给更大的数据处理任务,整体的内存使用量也将得到降低。如下图: 实现世界最快的学习速度! 富士通研究所开发的这两项技术已经部署在Caffe 深度学习框架当中,并在拥有64个GPU的计算机上使用AlexNet对学习时间进行了测试,其运行结果比单一GPU的运行速度快了27倍。与此前的技术相比,它的运行速度比16个GPU的配置快了46%,比64个GPU的配置快了71%。 利用这一技术,深度学习研发所需要的时间将极大缩减,例如机器人自主控制的神经网络模型开发。该技术还能够运用在汽车、医疗以及金融等各行各业,包括无人驾驶、病理分析以及股票价格预测模型开发等诸多应用领域。 富士通研究所的这两项技术将作为人工智能平台“Human Centric AI Zinrai”的一部分,预计在今年4月正式投入使用。今后,富士通还将为进一步提高人工智能学习速度而不断开发创新的技术。 文章摘自富士通中国 欢迎联系永信贵宾会集团咨询富士通产品信息 永信贵宾会集团联系方式 咨询热线:400-830-0107 永信贵宾会官网:www.yyhsjs.com 客户垂询邮箱:Customer@yyhsjs.com 客户垂询QQ:1305742380 地址:深圳市福田区深南大道1006号国际创新中心C座11楼 邮编:518026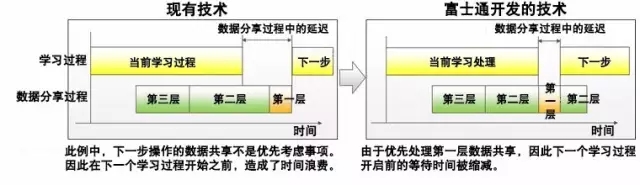



 粤公网安备 44030402001885号
友情链接: 金沙古酒 | 中青宝 | 宝德控股 | 宝德计算 |
粤公网安备 44030402001885号
友情链接: 金沙古酒 | 中青宝 | 宝德控股 | 宝德计算 |