 当前位置:
当前位置:服务热线
0755-83647532

发表日期:2017-03-02 文章编辑:管理员 阅读次数:
进入21世纪后,计算机的体系结构并没有停止前进的步伐,尤其是在处理器领域所取得的技术突破奠定了包括云计算、大数据,以及近几年炙手可热的机器学习的基础,在软件定义时代来临之后,硬件的作用却丝毫没有降低,反而越发显得重要。
随着制造工艺越来越接近极限,计算场景化的不断丰富,在通用计算场景下,可编程能力显的极为重要,在专用计算场景下,大规模并行与低延迟又变的不可或缺,面对这一前所未有的复杂局面,比较可行的办法是软件与硬件的高度协同,通过对硬件层面能力的控制权直接暴露给操作系统,乃至运行于用户态的Application来满足可编程与性能等不同场景的要求,这种做法比比皆是,其中之一就是NUMA(None Uniform Memory Acess)技术,接下来我们深入其中看一看这项技术的来龙去脉以及如何影响到云平台的。
术语
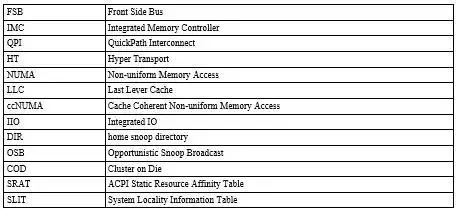
NUMA 结构简介
随着处理器的工作频率的提高和由于一些材料工艺限制导致处理器的发展朝向多core多socket带来一个明显问题- 我们所熟知的FSB结构在多个性能强劲的处理器面前会成为竞争点。为了解决这个问题,AMD于2003年在第一代Athlon64位处理器中首次采纳了HT(Hyper Transport)设计,并提出把内存控制器由北桥挪到了处理器管芯中的设计,随后Intel借鉴并于2004年提出了类似的设计,称之为QPI(QuikPath InterConnection),但是在Xeon中采用这项技术已经是2009年的Nehalem了,HT与QPI都采用的point-to-point interconnect技术,来保证处理器间的高速通信。结果如下图所示的:

每个处理器都有自己的IMC,连接到本地内存。这样在增加和提高处理器数量和工作频率的时候,本地内存的访问效率也可得到保证。 这也就是我们要讨论的NUMA系统。每个处理器和它本地的内存(加上有可能存在的处理器集成IO)构成一个NUMA节点。再以Intel为例,结合CBox和HA间的snooping protocal,共享的LLC的一致性也得以保证。事实上X86的NUMA系统也都是ccNUMA。
由于目前在用的Intel机器基本上都是2个NUMA节点的结构,所以经常在资料中提到的NUMA节点间的距离问题实际往往是不用考虑的。最新的Intel® Xeon® Processor E7-8860 v4和Intel® Xeon® Processor E5-4610 v4以上的CPU才支持8颗和4颗的系统配置,而服务器厂商出于成本考虑也会慎重考虑采用这样的配置。即使在多颗CPU的配置下,不同NUMA节点之间的距离问题在QPI的配备下也无须担心了,因为它提供任意两个处理器的点对点的直接通信。 下图较完整展示一个中端的系统,双Intel 2630 v4 CPU,10 cores (20 HT threads),4 memory channels,2 QPI Links,PCIe 40 Lanes Max。

从中可以清晰的看到,CPU0要访问远程CPU1节点的内存是需要经过QPI,因此产生额外的latency。QPI的速率越快,这个latency就越小,然而此处理器的QPI速率是8 GT/s,换算后是要比这个系统所支持的最低的1600 MHz DDR4的内存的访问频率慢的。访问远程内存即便有LLC的命中, 系统带着Home Snoop with DIR + OSB的支持,也是要产生额外的开销的。同样道理,NUMA节点里所集成的IIO远程访问是也有额外的latency。对于这个系统来说就是访问远程的集成PICe也要经过处理器间的QPI。事实上Intel的COD技术引入后,因为它启用后会在一个处理器上划分两个NUMA节点来提高每个节点内Ring Bus的带宽进而提高本地LLC在多核下的访问速度,本地LLC访问性能得到提升,远程的LLC的访问却未有提升。 并且需要软件开发人员的注意的是,与绝大多数常见的NUMA系统不同,这时在同一socket上由COD逻辑划分的NUMA节点与其它socket上的NUMA节点的距离是不同的,这可以在SRAT和SLIT中读到具体信息。
当然,免得麻烦,用户可以简单粗暴的选择隐藏NUMA,启用BIOS的Node Interleaving项去提供interleaved memory structure 影射所有节点的内存, 不过这样会产生粗略估计一半内存访问落到的实际远程内存,系统无法发挥出最优性能。
讨论过NUMA结构下系统性能提升和所须要避免的一些使用方式,接下来的两个章节分别探讨Linux以及基于Linux的云计算平台OpenStack提供怎样的机制让我们更有效的使用NUMA结构系统。
NUMA in Linux
对于NUMA系统来说,Linux会为每一个NUMA节点创建一套内存管理对象的实例,每个节点包含DMA, DMA32, NORMAL等Zone。当某个节点下的某个Zone无法满足内存分配请求时,系统会咨询zonelist进而决定后备Zone的选择顺序。当本地Zone NORMAL内存不足时,黙认顺序是从本地的Zone DMA32和DMA尝试,然后再尝试其它的节点。此顺序可以由numa_zonelist_order参数更改,比如先去尝试远程节点的Zone NORMAL以节省比较稀缺的Zone DMA32和DMA内存(当然,非黙认NUMA policy有可能偏好远程节点)。
NUMA Policy
Linux memory policy用来指定在NUMA系统下kernel分配内存时具体从哪个节点获取(Interrupt Context下不受policy限制 ,详见alternate_node_alloc 和alloc_pages_current)。系统的黙认policy为优选当前节点。不过在系统启动阶段用的是interleave mode分配内存,以避免过载启动节点,同时也因为系统也无法预测运行时那个节点的内存访问会更多。Memory policy可以作用于task和VMA上。作用于task时可以限制对于当前task的所有内存分配,并且会被child task继承。VMA policy用来限制一个vm area的内存分配。此时需额外注意,它只作用于anonymous pages(详见alloc_pages_vma)并且被使用同一个地址空间的task共享。VMA policy优先应用于task policy。
Linux memory policy 支持四种不同的模式– DEFAULT,BIND,PREFERRED,和INTERLEAVED。Default意味着用下级备选policy(系统的黙认policy为最后选择),BIND强制内存分配必须在指定节点上完成,PREFERRED模式在内存分配时会优先指定的节点,失败时会从zonelist备选,INTERLEAVED会使内存分配依次(VMA的page offset或task的node counter)在所选的节点上进行。
mbind和set_mempolicy系统呼叫用来更改当前task和task地址空间里的VMA的policy。mbind更改VMA policy黙情况下只对之后分配的内存有效,不过可以通过move或move_all 标旗来强制移动已分配的页面。set_mempolicy更改task policy后,之前不符合此policy的页面会逐步被NUMA Balancing挪到指点的节点。
NUMA Balancing
Automatic NUMA balancing可以将task迁移到它大量访问内存的节点上,同时将task错误放置的内存页在晚些时候这个页面被访问到时按照policy的指示移动(当用户改变内存policy)。这主要是依赖内核中的task_numa_work和do_numa_page两段代码。前者会被时钟中断处理加到task work上,然后在返回用户态前(评估signal之前)运行,用来去掉此task的内存区的页表(数量由numa_balancing_scan_size决定)PRESENT位并且用一个预留位来标示此页即将产生的Page Fault为NUMA Page Fault。它发生的频率可以由numa_balancing_scan_period等参数调整。后者在Page Fault产生时用来处理NUMA Page Fault,来真正移动不符合内存policy的页面。迁移task也是在此时跟据远程内存访的统计来进行的。在无需挪动页面时此种Page Fault的开销很小,只须将页表的PRESENT位加上。用户也可以主动手工移动内存页面到其它NUMA节点,move_pages和migrate_pages两个系统呼叫提供了这样的功能。这里特别提及一下migrate_pages系统呼叫,与大多其它NUMA相关的系统呼叫不同,此呼叫可以用来移动其它task(不局限于当前task)的内存页面到不同的NUMA节点上,这也使用户态下直接调整不同NUMA节点内存使用的工具可以实现, 比如migratepages工具。
cpuset
cgroup的cputset可以用来限定一个task可以在哪(几)个CPU上运行,以及它可以在哪些节点上获取内存。sched_setaffinity,mbind和set_mempolicy的行为也都是要受到cpuset的限制,也可理解为cpuset有着更高的优先级。一个cpuset关连一组CPU和内存节点,系统中每个task都要搭载到一个cputset。黙认情况下为root cpuset,此时充许使用所有的CPU和内存节点。通过cpuset具体属性的调整可以实现很多具体的需求。比如创建一个大的mem_exclusive cpuset去限制(hardwall)某些task在内核态下的内存分配只能在某些节点上,同时为每(几)个task创建子cpuset来限定这些task在用户态下可分配的内存,这样这些task可以在预定的节节上共享page cache等内核数据,同时每(几)个task又可定义在用户态下自己可使用的资源。
NUMA profile
有关不同NUMA节点内存使用的信息可以在/sys/devices/system/node/nodeX 下的meminfo中得到, 同目录下的numastat中可以得到在内存分配过程中优选节点备选节点的页分配量,使用numastat工具还可以方便的获得指定task的这些信息。更细粒度的信息采集需要用perf来直接收集有关NUMA的硬件事件,比如远程节点LLC的命中和远和内存的访问信息。具体的可收集事件不同的微架构有所不同,需要参考Intel提供的文档。
NUMA virtualization support
Libvirt/Qemu是在Linux下常见的虚似化方案,也是OpenStack的主要选择。Libvirt在定义虚似机时充许用户指定Qemu虚似机进程的memory policy和虚似机及其vcpu绑定的物理cpu。在虚似机运行时也可以通过命令更改虚似机及其vcpu的绑定,但memory policy在运行时是无法改变的,因为更改memory policy的系统呼叫只可以作用由当前task,Libvirt需要更改memory policy然后让虚拟机进程(子进程)继承。虚拟机及其vcpu的绑定不受此限制,因为绑定是cgroup和sched_setaffinity支持的,而它们不受此限制。Qemu也支持将物理机的NUMA拓补结构“直通”给虚拟机。
-object memory-backend-ram,size=1024M,policy=bind,prealloc=on,host-nodes=0,id=ram-node0
-numa node,nodeid=0,cpus=0-1,memdev=ram-node0
-object memory-backend- ram,size=1024M,policy=bind,prealloc=on,host-nodes=1,id=ram-node1
-numa node,nodeid=1,cpus=2-3,memdev=ram-node1
如上所示,显示的定义两个memory backend, 通过bind memory policy去将这两个VMA(Qemu为每个memory backend创建一个anonymous VMA)分别绑定到两个不同的host NUMA节点上。
NUMA in OpenStack
OpenStack在Juno和Kilo以后分别加入了虚拟机NUMA节点布署拓补与vCPU绑定功能 。接下来章节我们一起看下这两个NUMA相关的功能。
虚拟机NUMA节点布署拓补
此功能是通过flavor的extra specs (numa_nodes , numa_cpus , 和numa_mem )提供给用户的。当虚拟机的vCPU上内存要求很高, 超出了物理机单个NUMA节点可提供的数目时,或是某些情况当虚拟机里的任务在多核上都产生极大的内存访问量使单个节点的内存带宽(甚至是访问LLC对Ring Bus竟争)压力过大,此功能可以用来显示的指定虚拟机如何NUMA利用物理机上多个NUMA节点。下面的示例是将vCPU 0,1与2,3分别绑定到NUMA节点0与1上,同时要求1024与2048兆内存分别在节点0与1上分配。
hw:numa_nodes=2
hw:numa_cpus.0=0,1
hw:numa_cpus.1=2,3
hw:numa_mem.0=1024
hw:numa_mem.1=2048
vCPU绑定
通过flavor的cpu_policy选项(设置为dedicated)也可以将虚拟机的vCPU具体绑定到物理机的某个core上,来满足接有实时性较高的虚拟机任务的需求。配合内核的isolcpus启动参数去把一些cpu放到isolated sched domain预留起来,以避免其它用户态进程被平衡调度过来,由此保证vcpu不被抢占。
References
1. An Introduction to the Intel ®QuickPath Interconnect January 2009
2. Intel ® Xeon ® Processor E5 v4 Product Family Datasheet Volume 2: Registers June 2016
3. Iakovos Panourgias - “NUMA effects on multicore, multi socket systems”, 9/9/2011
4. Frank Denneman - “NUMA Deep Dive Part 2: System Architecture” - http://frankdenneman.nl/2016/07/08/numa-deep-dive-part-2-system-architecture/
6. Linux Memory Policy - https://www.kernel.org/doc/Documentation/vm/numa_memory_policy.txt
7. joemario - “C2C - False Sharing Detection in Linux Perf” - https://joemario.github.io/blog/2016/09/01/c2c-blog/
7. CPU topologies - http://docs.openstack.org/admin-guide/compute-cpu-topologies.html
8. Steve Gordon - “Driving in the Fast Lane – CPU Pinning and NUMA Topology Awareness in OpenStack Compute” - http://redhatstackblog.redhat.com/2015/05/05/cpu-pinning-and-numa- topology-awareness-in-openstack-compute/
文章摘自英特尔精英汇
欢迎联系永信贵宾会集团咨询英特尔产品信息
永信贵宾会集团联系方式
咨询热线:400-830-0107
永信贵宾会官网:www.yyhsjs.com
客户垂询邮箱:Customer@yyhsjs.com
客户垂询QQ:1305742380
地址:深圳市福田区深南大道1006号国际创新中心C座11楼
邮编:518026


 粤公网安备 44030402001885号
友情链接: 金沙古酒 | 中青宝 | 宝德控股 | 宝德计算 |
粤公网安备 44030402001885号
友情链接: 金沙古酒 | 中青宝 | 宝德控股 | 宝德计算 |